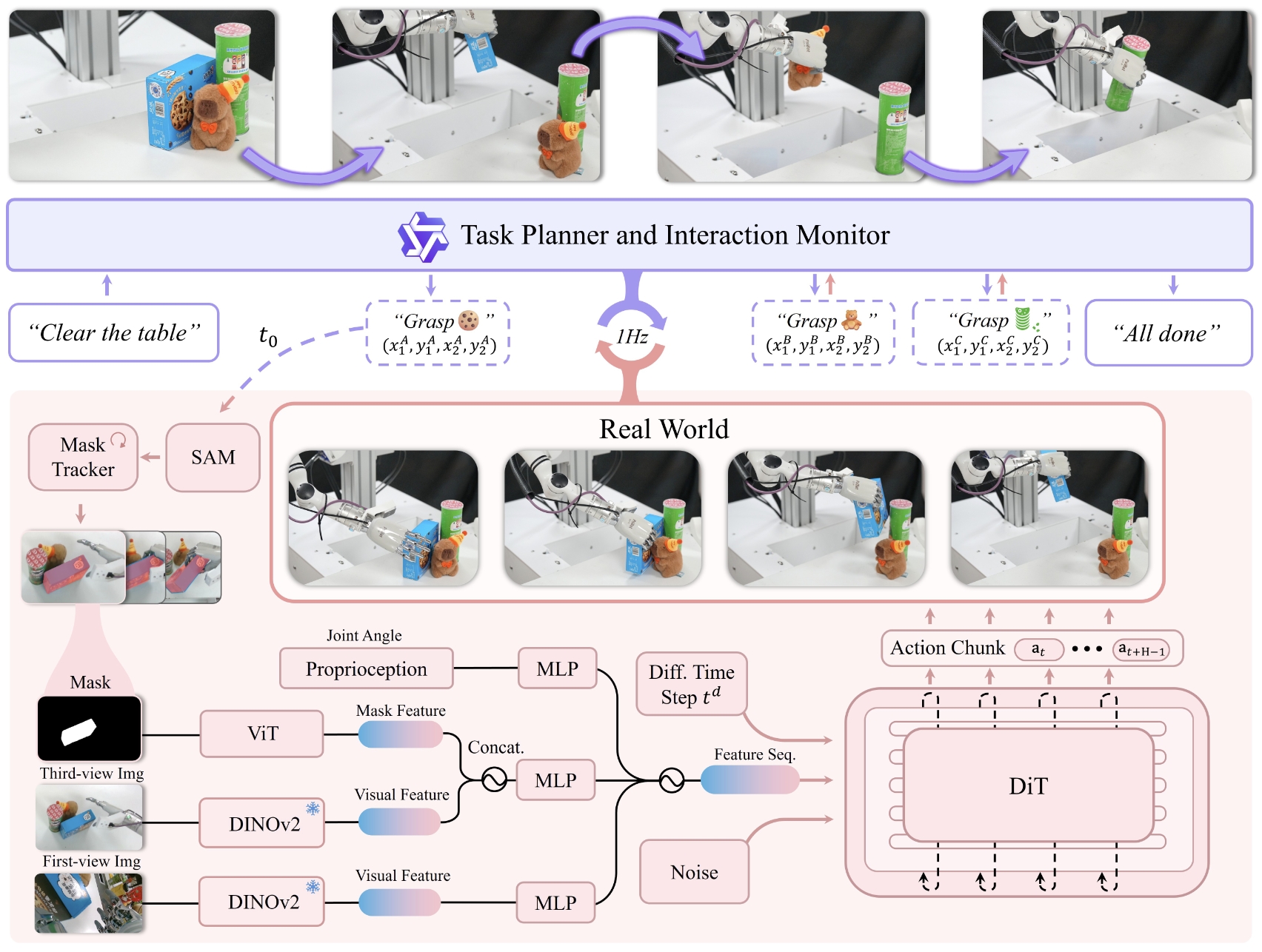
DexGraspVLA adopts a hierarchical architecture composed of an off-the-shelf VLM-based high-level
planner and a diffusion-based low-level controller.
Given a cluttered scene, the planner grounds the user prompt, e.g., "clear the table", in the observation and proposes grasping instructions \(\{l_i\}\) sequentially.
For each instruction \(l\), e.g., "grasp the cookie", the planner identifies the target object \(A\) from the head image \(\mathbf{I}_{t_0}\)
and marks its bounding box \((x_1^A, y_1^A, x_2^A, y_2^A)\) at initial time \(t_0\).
The controller consists of four parts:
- Two segmentation models including SAM, which obtains the object's mask \(\mathbf{m}_{t_0}\) at \(t_0\), and Cutie, a video segmentation model that continuously tracks the mask \(\mathbf{m}_t\) during each grasping process.
- Three vision encoders including two frozen DINOv2 that extract features from the third-view head-camera image \(\mathbf{I}_t^h\) and the first-view wrist-camera image \(\mathbf{I}_t^w\), and a trainable ViT that deals with the mask \(\mathbf{m}_t\).
- Three MLP projectors that map the visual features and robot proprioceptive state into the same feature space, forming a feature sequence.
- A DiT that predicts an action chunk from \(\mathbf{a}_t\) to \(\mathbf{a}_{t+H-1}\).
During the controller's grasping process, the planner monitors the execution and triggers a scripted placing motion when grasping succeeds. After each grasping attempt, the planner resets the robot and proposes a new grasping instruction. This process continues until the user prompt is fully completed.
The controller is trained on a dataset consisting of 2,094 successful grasping episodes in cluttered scenes. These demonstrations are collected at typical human motion speeds, with each episode taking approximately 3.5 seconds. In total, this amounts to roughly two hours of data.